Features
- Is model and framework agnostic
- Provides token usage, estimated cost, duration, input, and output
- UI to show sequence of events
- Supports evaluation
- Supports annotation
- Supports user feedback
- Supports async functions
- Option to add custom trace name
- Option to log custom metadata
- Option to set trace result
Logging LLM requests
LLM request monitoring is used to track the execution of your AI model. These can be used to capture:- Model configuration like model name, model configurations, prompt templates, etc.
- Execution details such as prompt tokens, completion tokens, cost, etc.
- API-level metrics like request latency, rate limit errors, etc.
- OpenAI tool calls in JSON format
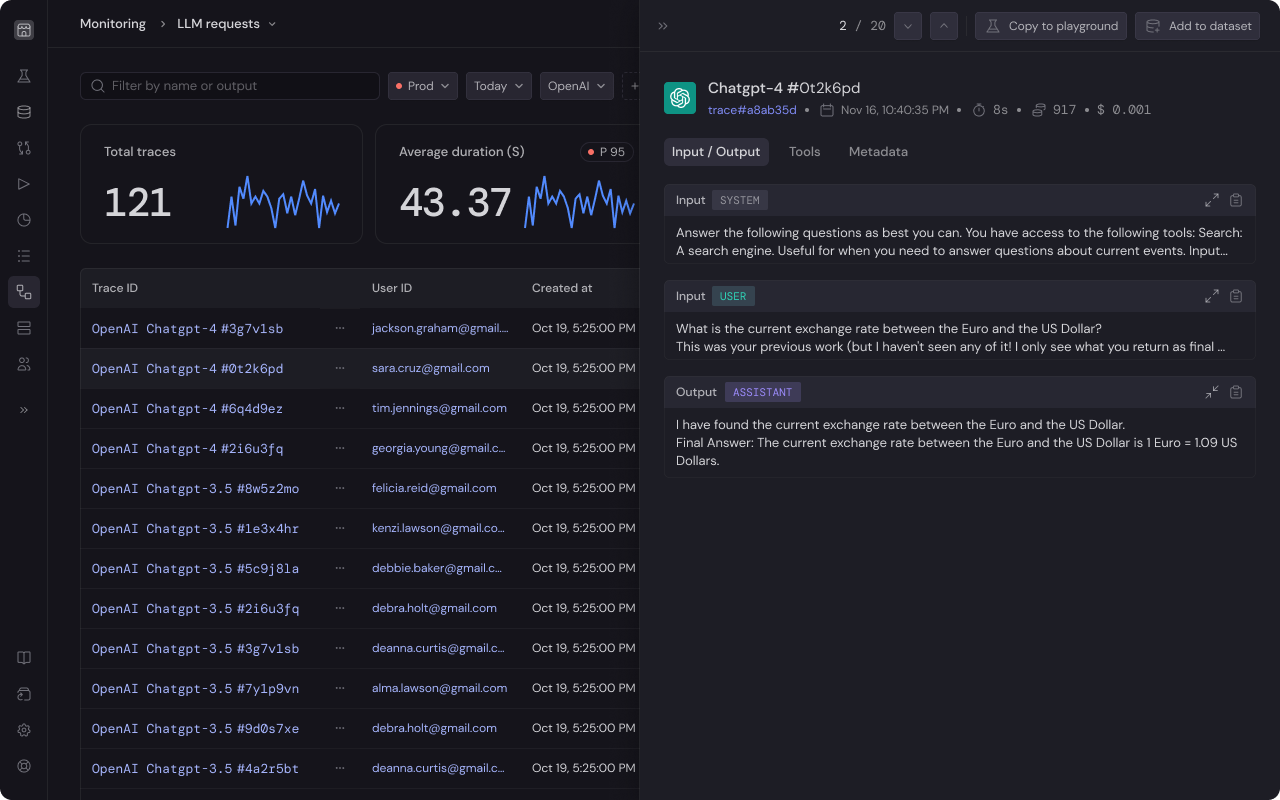
Use cases
For example, you are creating a AI travel agent to assist with booking trips. This bot needs to accurately gather flight ticket details from scrapping user emails. With logging LLM Request, you can:- Track and Fix Errors: Test the same task repeatedly to see how often and where your bot throws an errors.
- Ensure Quality: Verify that your bot is correctly identifying flight prices, dates, and booking details. You can check if the bot is giving the user right response based on the email input.
- Improve User Experience: Keep track of the response time for each request. This helps find any delays in the bot’s responses, leading to improvement in how users interact with the bot.
Instruction
If you haven’t authorize Baserun, please refer to the getting started with SDK > Authentication section for setup instructions.Example
You can use Baserun with tests while iterating on your features, utilizing it for debugging and analysis, or in the production environment to monitor your application.For more information refer to Testing.
Tracing end-to-end pipeline
A Trace comprises a series of events executed within a pipeline. Tracing enables Baserun to capture and display the workflow’s entire lifecycle, whether synchronous or asynchronous. For example, consider the case of an AI bot used to automate phone calls. The process begins with the bot initiating a call to the user. While the call is in progress, the conversation is transcribed into text. Subsequently, the bot analyzes the transcribed text to produce a response or message. Once the response is crafted, it is converted into audio. Finally, the AI system transmits the audio message.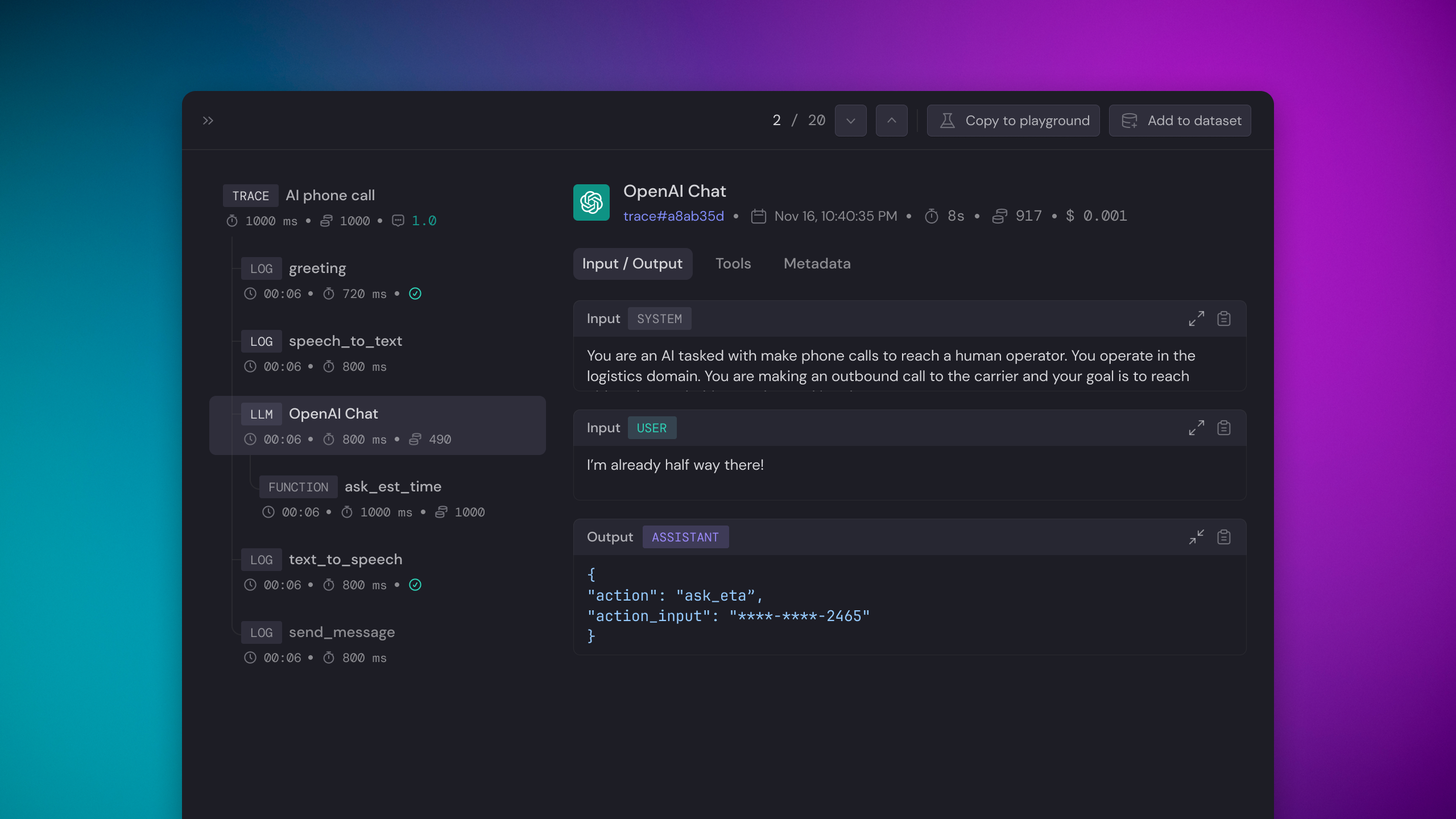
If you are using Next.js, please reference Monitoring > Tracing with
Next.js.
If you are using Lambda, please reference Monitoring > Tracing with
Lambda.
Instruction
To trace a function, wrap it withbaserun.trace. In the following example, our workflow constitutes two LLM calls.
- List out three activities to do on the moon
- Choose the best activity among the three
Example
Demo projects
Python example repo,Typescript example repo If you have any questions or feature requests, join our Discord channel or send us an email at hello@baserun.ai
Advanced tracing
Add trace name, set trace result, add custom metadata
Custom logs
Logging non-LLM API calls or custom functions