Logging LLM requests
Get insight into individual LLM request, including prompt templates, input, output, duration, token usage cost, etc. Collect datasets for continuous iterations (fine-tuning, testing).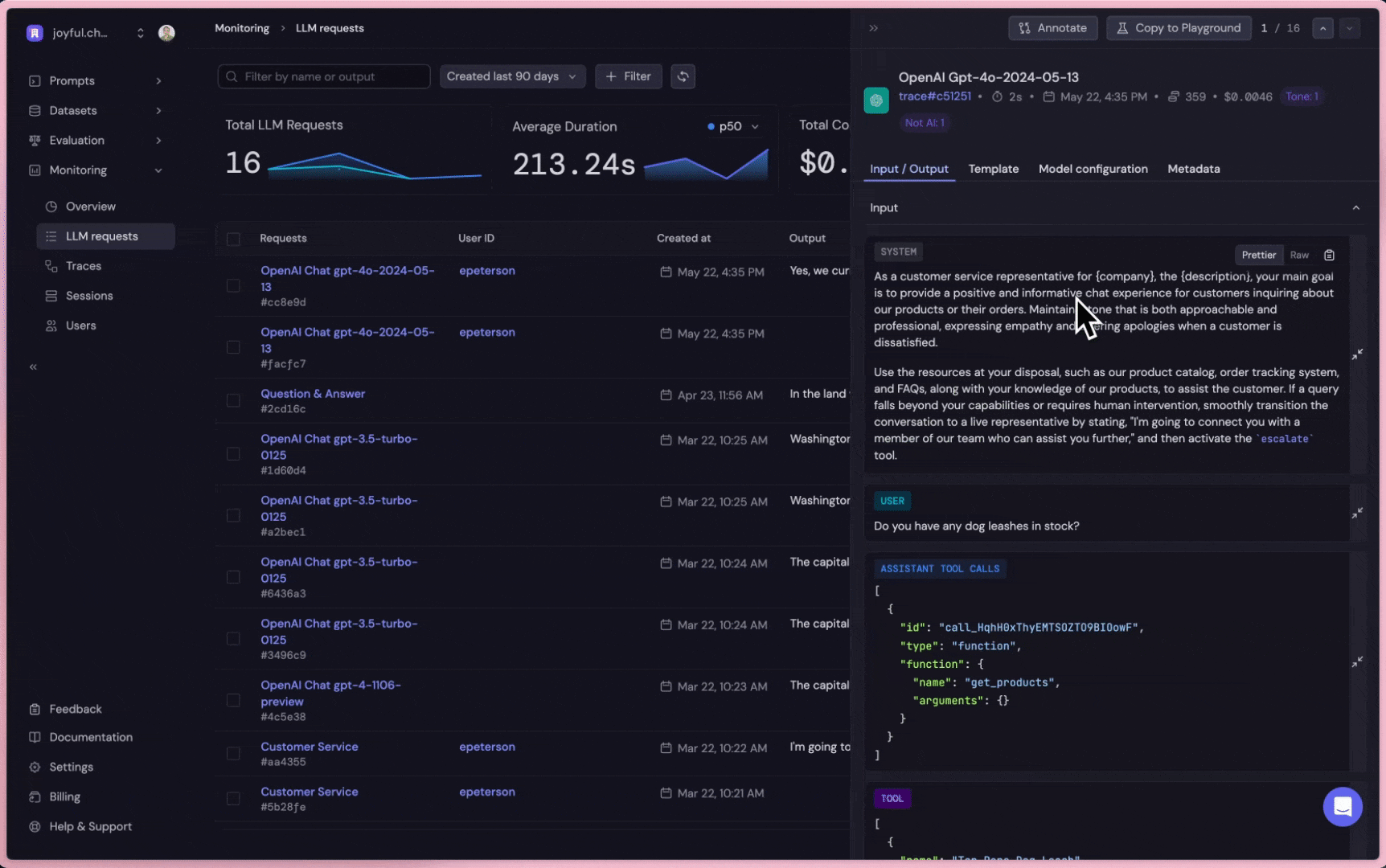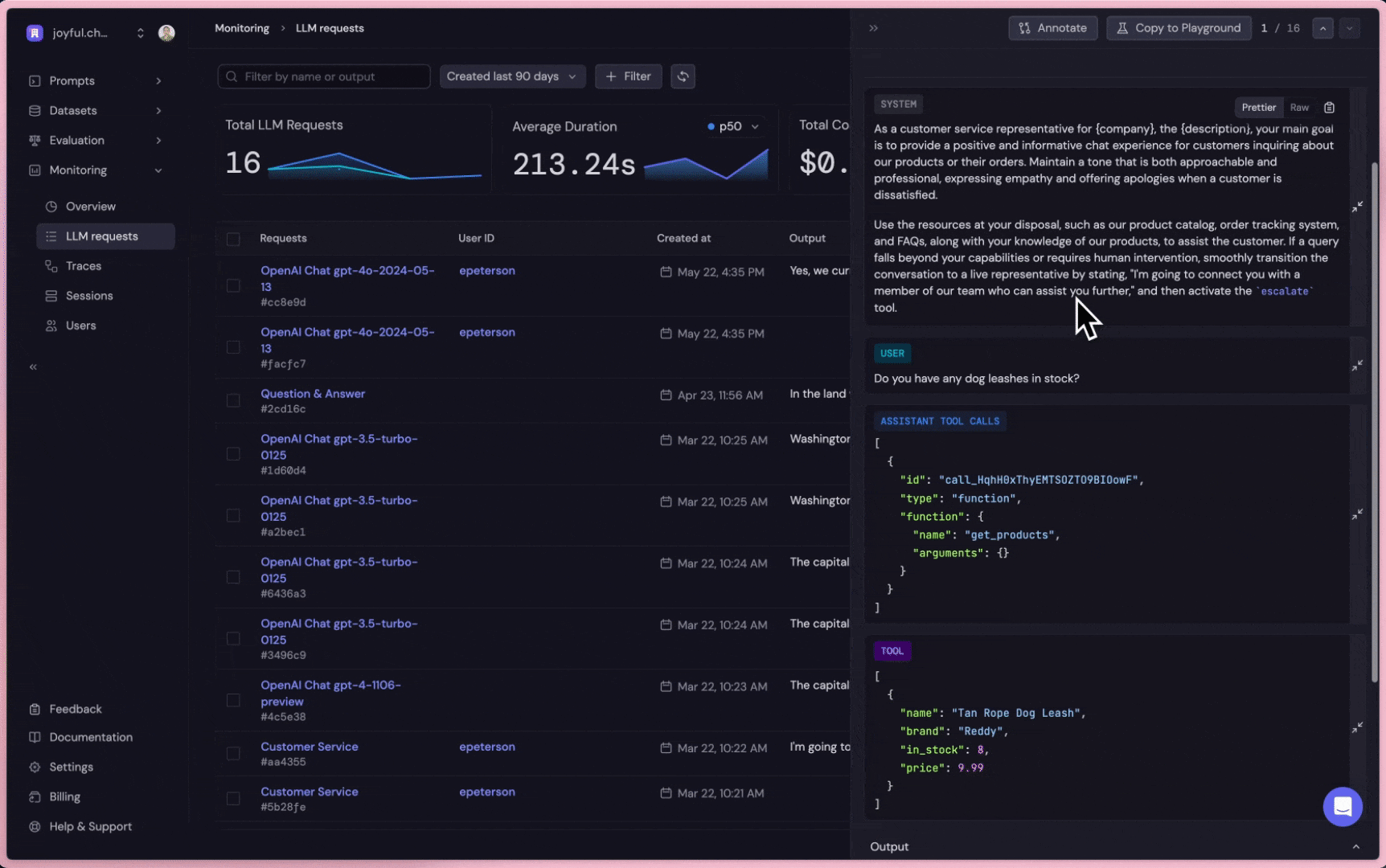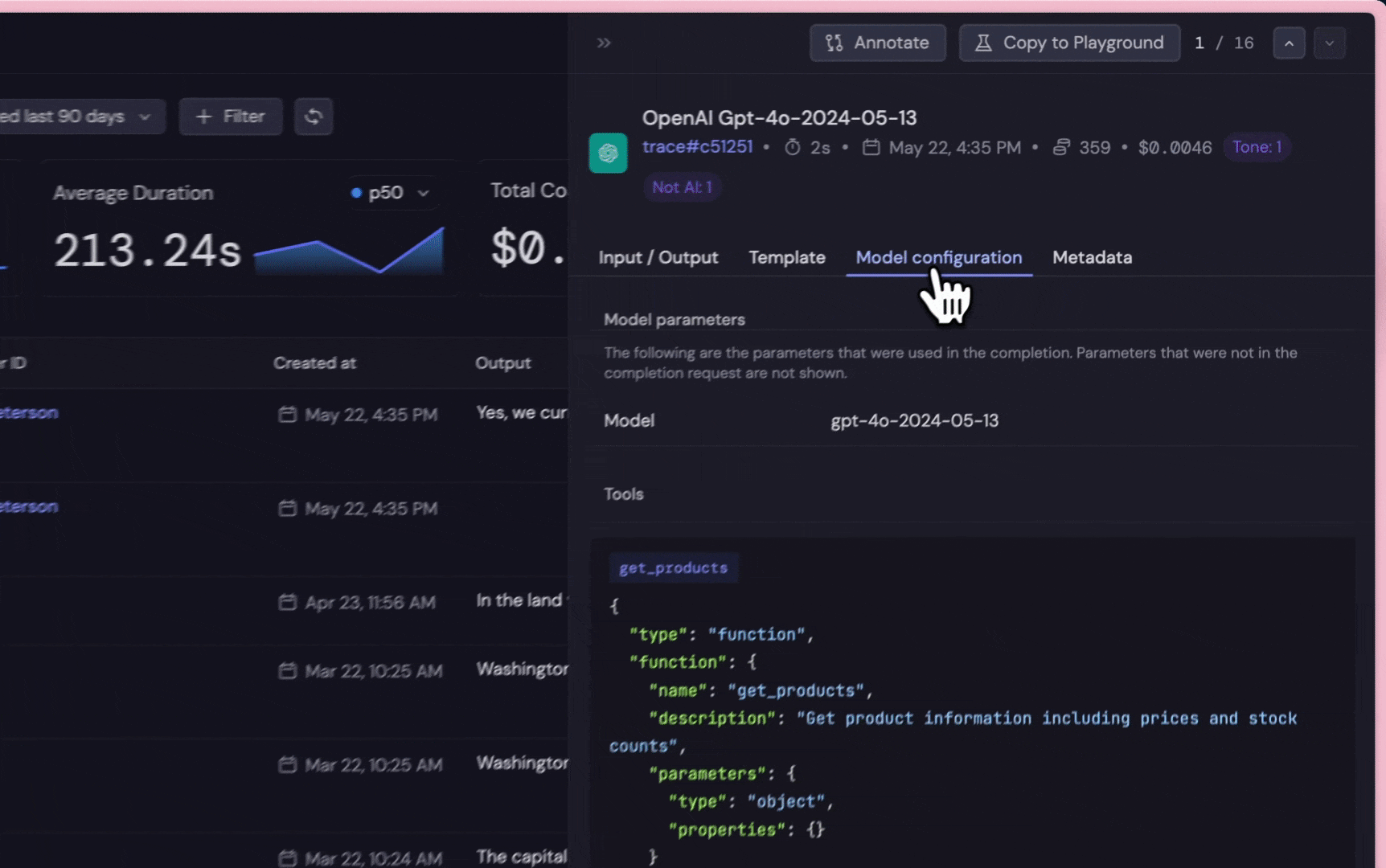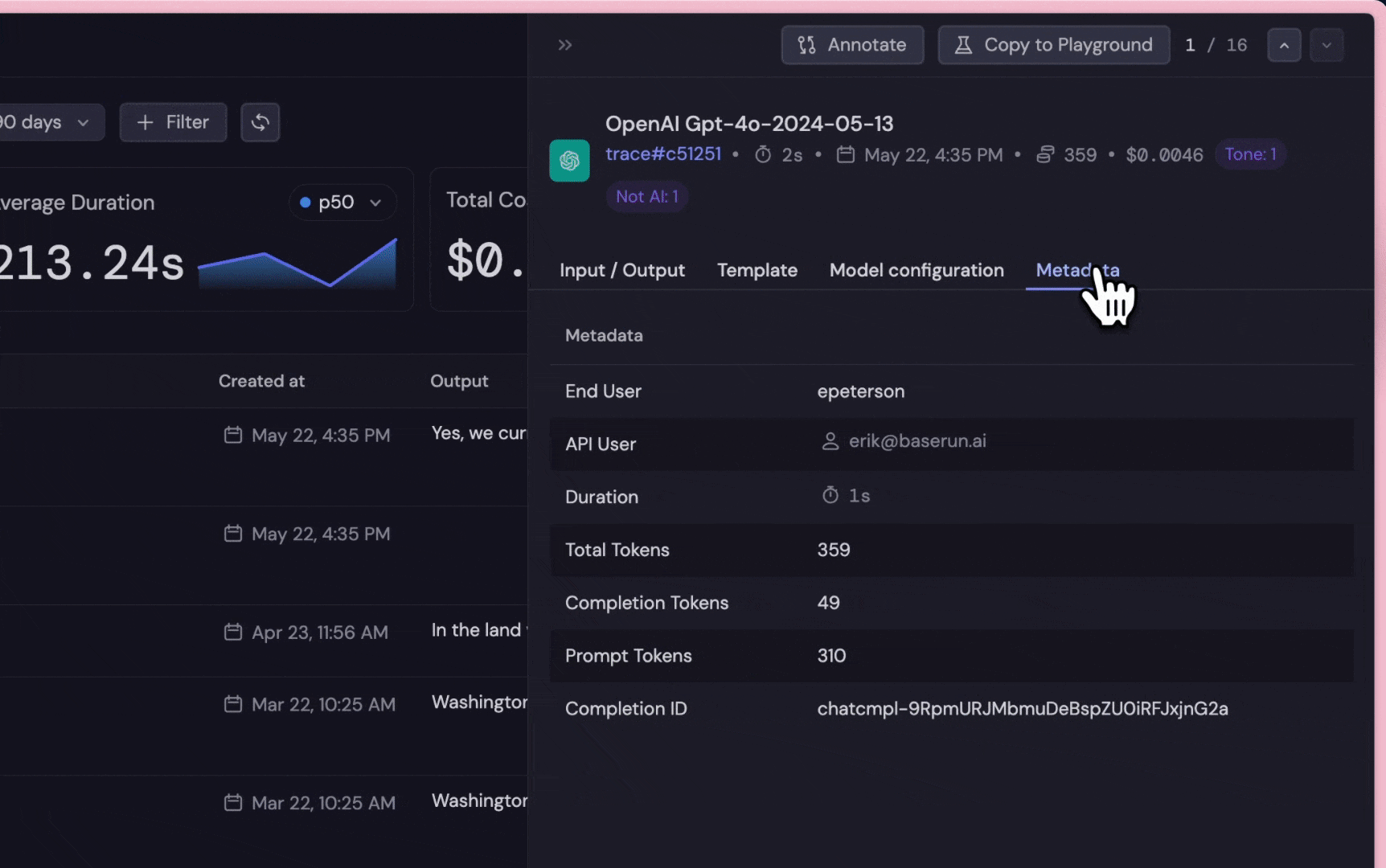
LLM request represents a single query to an LLM provider. Baserun refers to the returned object as a Completion.
If the request is successful, Baserun logs the completion in the UI as shown above. A completion includes the
input and output of the request, along with metadata such as the user, request ID, and model configurations.
If the request fails, Baserun logs the error code and message in the LLM requests table.
Arguments
Beyond the default settings, users can customize additional arguments to improve analysis and data collection: Specify the following properties as keyword arguments when creating an LLM request (e.g., using completions.create). These can also be adjusted on the completions object returned by the client.Arguments: name, completion_id, user
Arguments: name, completion_id, user
stream.
Instructions
1
Install Baserun SDK
2
Set the Baserun API key
Create an account at https://app.baserun.ai/sign-up. Then generate an API key for your project in the settings tab. Set it as an environment variable:
3
Import and Init
In order to have Baserun trace your LLM Requests, all you need to do is import
OpenAI from baserun instead of openAI. Creating an OpenAI client object automatically starts the trace, and all future LLM requests made with this client object will be captured.4
Alternate init method
If you don’t wish to use Baserun’s OpenAI client, you can simply wrap your normal OpenAI client using init.
Tracing end-to-end pipelines
A Trace comprises a series of events executed within an LLM chain (also called a workflow, among other names). Tracing enables Baserun to capture and display the LLM chain’s entire lifecycle, whether synchronous or asynchronous. Using Baserun, traces are tied to the client object of the library you are using. For example, if you are using the OpenAI library, you would create anOpenAI client object imported from baserun. When that client object is used all completions are automatically traced.
Arguments
These arguments can be passed when instantiating yourclient object, or can be set after instantiation.
Arguments: name, completion_id, trace_id, user, session, result, metadata
Arguments: name, completion_id, trace_id, user, session, result, metadata
string
Custom name of the trace
UUID
Created by Baserun but can be overridden by the user.
string
An identifier for the end user. Can be any string, e.g. a user ID or email.
string
An identifier for the current session. For example, you might user a session ID from your application framework or authenticiation library.
string
The output or outcome of the trace.
object
Instructions
In the following example, this pipeline has two LLM calls. Create a client at the beginning of the function you want to trace, and pass the client anywhere you want to use the same trace.trace_id. If you wish to associate an LLM request with a trace after the trace has completed, see the example below. Another common use case is when you want to add user feedback or tags to a trace after the pipeline has finished executing.
Supported Models
At the moment, the Baserun Python SDK 2.0 supports all models using OpenAI library and Anthropic library, regardless of the underlying model’s provider. We are continuously adding support for new models. If you have a specific model you would like to use, please reach out to us at hello@baserun.ai or join our community. If you use another provider or library, you can still use Baserun by manually creating “generic” objects. Notably, generic completions must be submitted explicitly usingsubmit_to_baserun(). Here’s what that looks like: