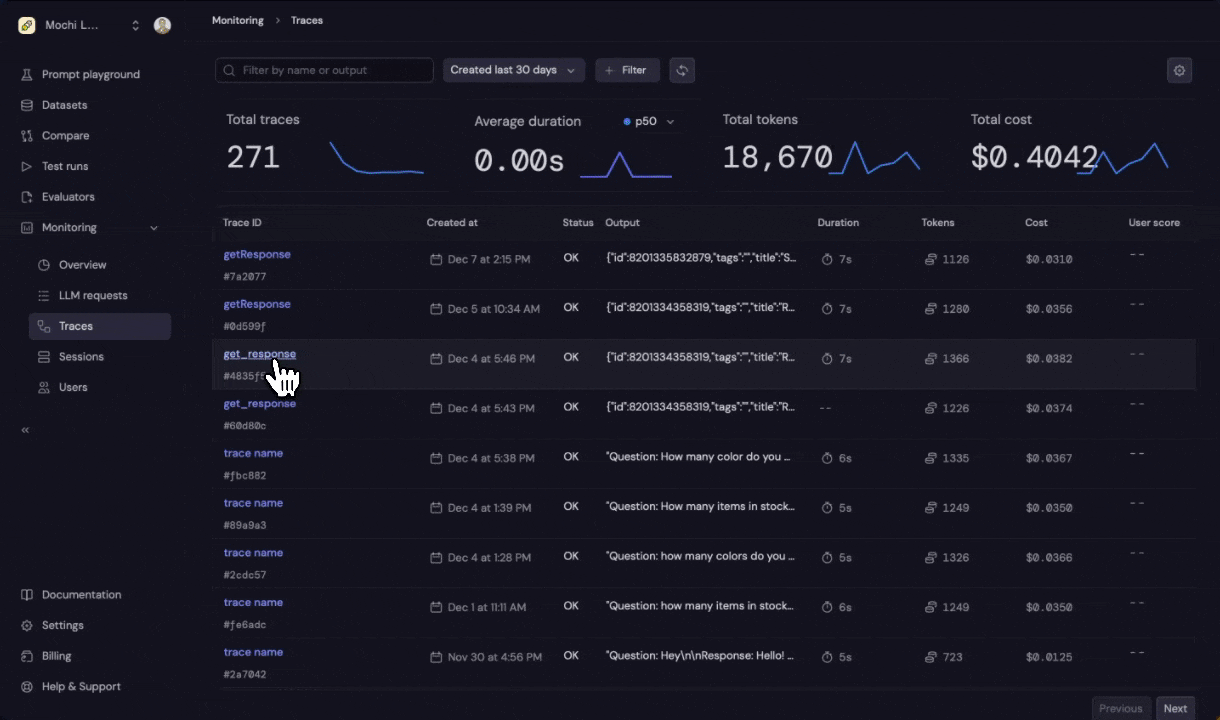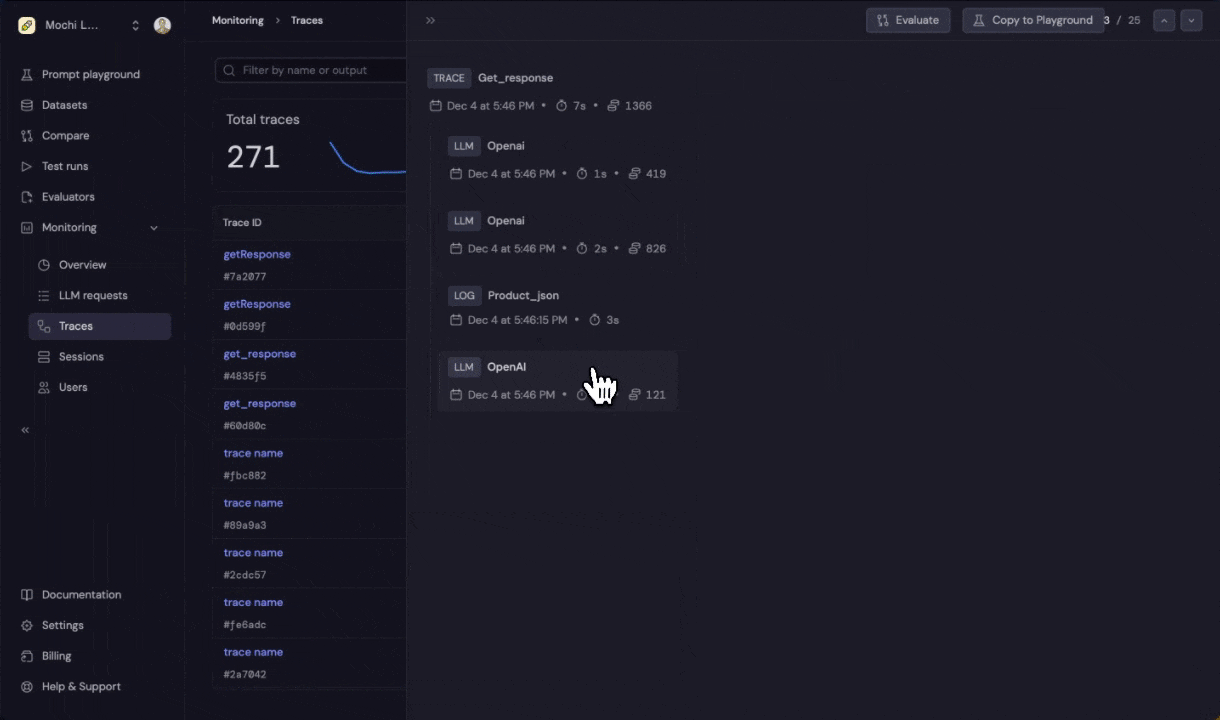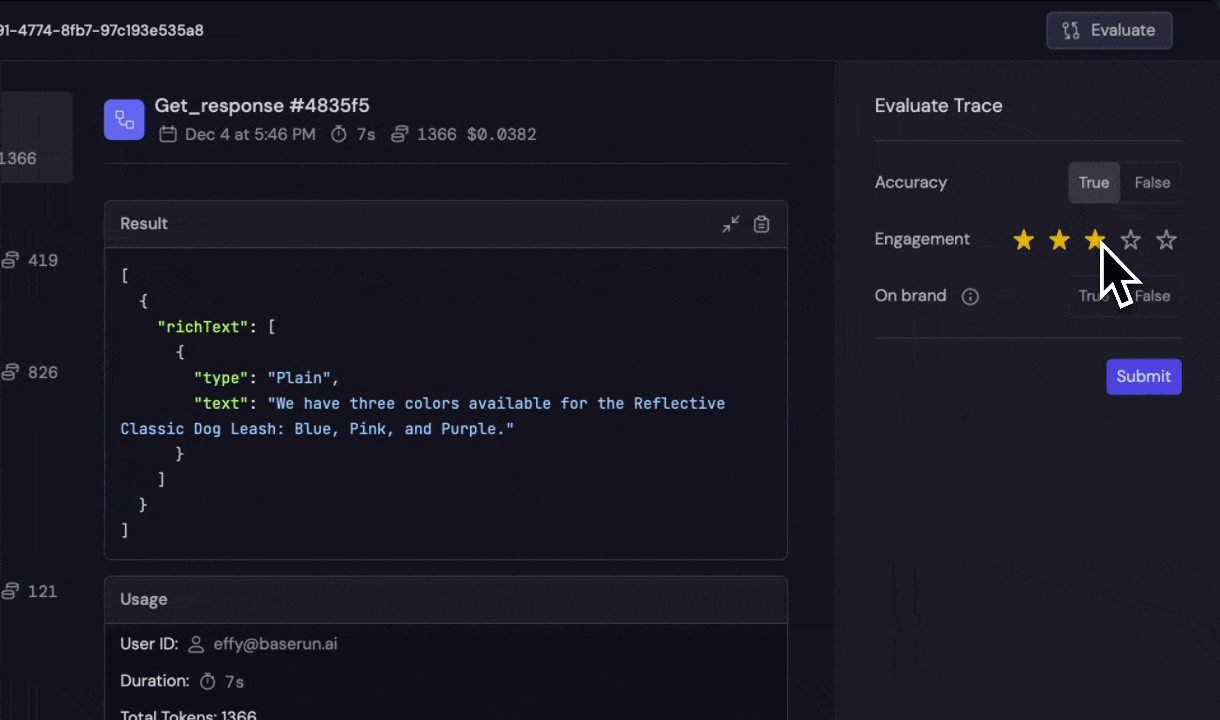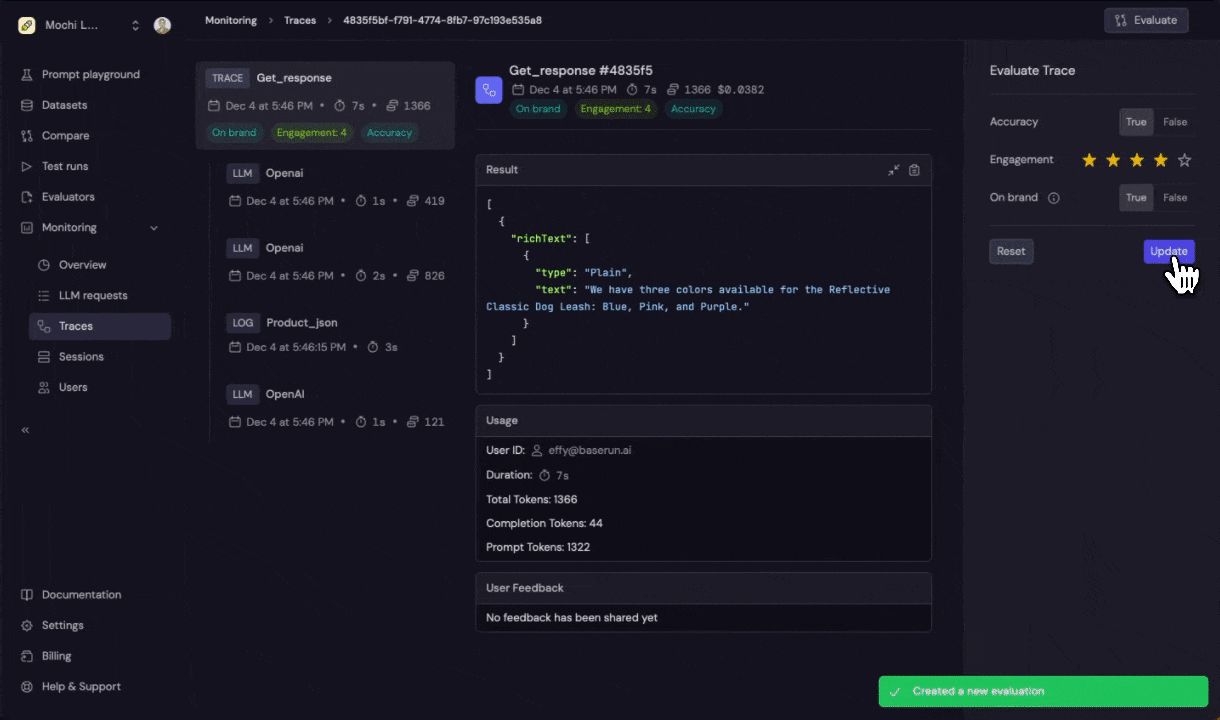
- Boolean: True or False result.
- Number: 1-5 scale.
- Enum: Multiple options.
Create a new evaluator
Navigate to the Evaluators tab and click on the 'New evaluator' button
You will be prompted to select an evaluator type. Select the Human
Evaluator.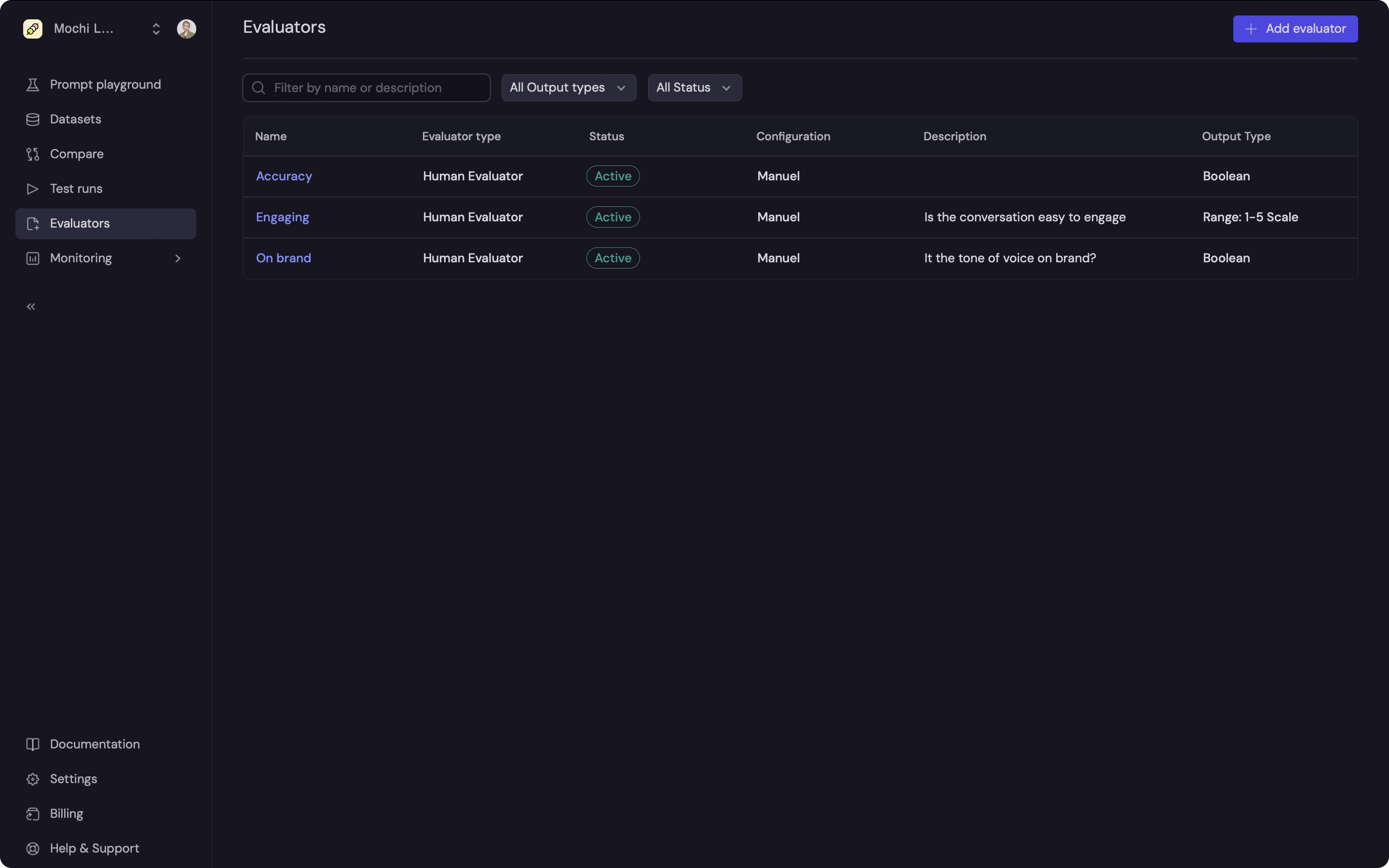
Navigate to the Evaluators tab and click on the 'New evaluator' button

