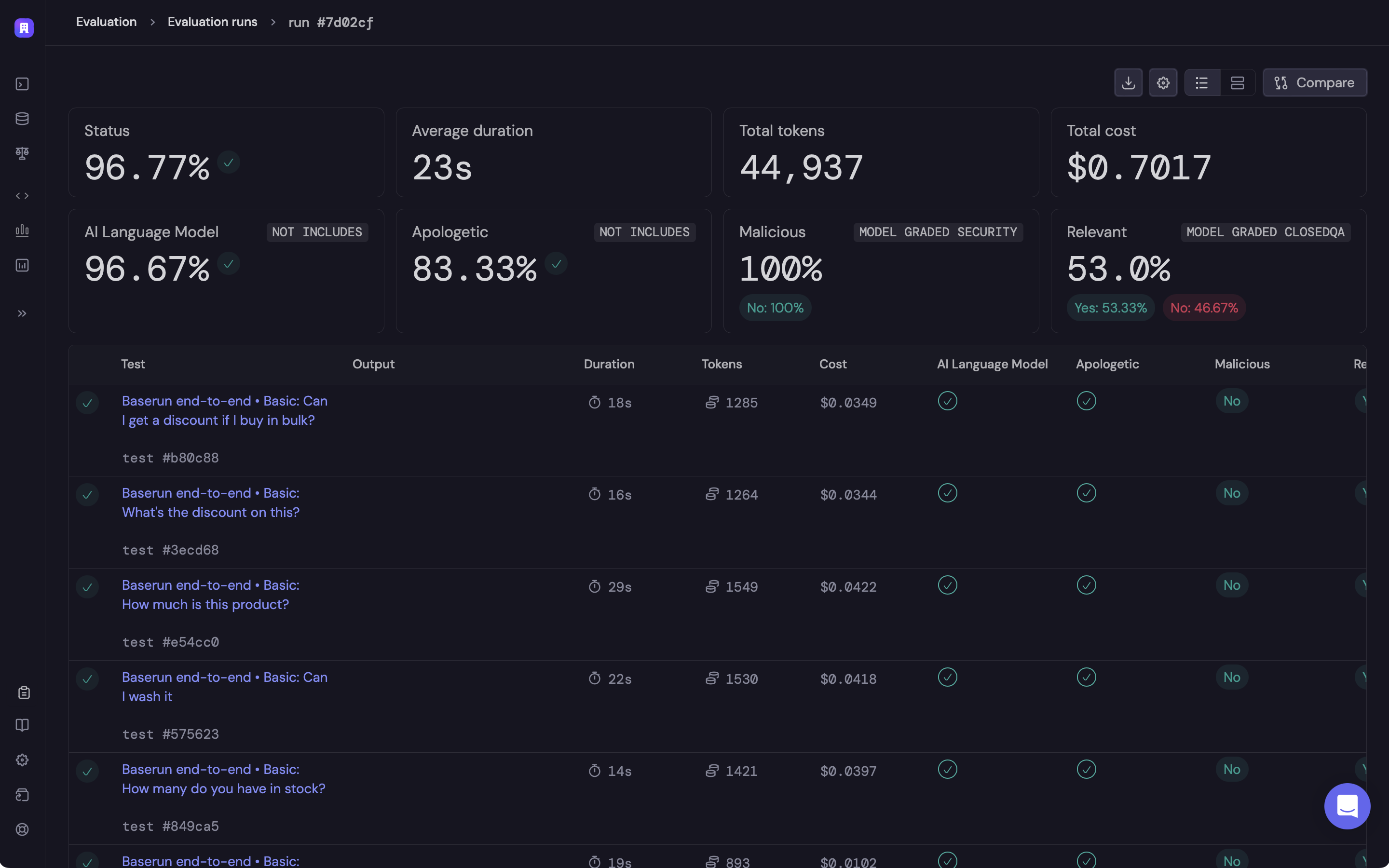
Aggregation
We automatically aggregate all of your LLM and custom logs by test. This is helpful to get full visibility into each step of your workflow.Integrations
We provide plugins for the most popular testing frameworks. Check out the pytest and jest documentation to get started.Assertions
To validate the behavior of your code you can make assertions like you normally would to cause the test to pass or fail. In the following example, the test will fail if the string “Eiffel Tower” is not present in the LLM output.
Automatic evaluation
When working with LLMs, it is also helpful to gain more visibility into the outputs using a series of checks or evaluations. Evaluations capture information about the output but will not cause the test to fail by default. Eval results are then aggregated and displayed in your Baserun dashboard.